4차 세션: 군집화
안녕하세요. 큐시즘 대외홍보팀 이지원입니다.
이번 포스팅은 이전 포스팅에 이어
두 번째 세션 군집화에 대한 세션일지입니다.
이전 인공지능과 관련된 교육 포스팅은 아래 링크를 참고해주세요!
2019/11/07 - [KUSITMS 교육자료] - [큐시즘 4차 교육 세션(1)] CRM 마케팅
그럼 4차세션, 두 번째 포스팅 시작합니다!

양용준 교육자의 군집화
군집화(Clustering)
군집화란 대표적인 비지도학습 방법으로 개체들이 주어졌을 때
이를 몇 개의 군집 (Cluster)로 나누는 과정을 의미합니다
그렇다면 이번에는 군집화에서의 지도학습과 비지도학습의 개념에 대해
좀 더 자세하게 알아보도록 하겠습니다.
지도학습과 비지도 학습
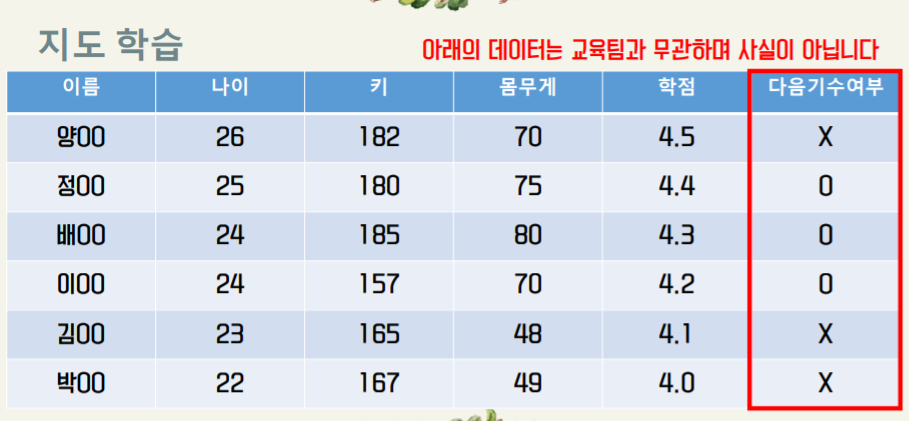

(A) 지도학습(Supervised learning)
지도학습이란 어떠한 기계학습 알고리즘에 데이터 집합을 제공할 때 이 데이터에 정답이 있는 상태를 말합니다.
위의 왼쪽 예시에서와 같이 각 인물에 대한 데이터에 O/X 형태의 정답을 함께 학습시키는 경우에 해당합니다.
(B) 비지도학습 (Unsupervised learning)
비지도학습이란 지도학습과는 달리 특정 데이터에 대한 학습시킬 정답이 주어져이 있지 않은 상태를 말합니다.
뉴스, 인간 DNA, SNS 관계 등을 분류할 때 사용되는 학습방법입니다.
군집분석

오늘 세션에서는 위의 그림과 같이 비슷한 특징을 가진 개체끼리
군집(Cluster) 분석 방법에 대해 구체적으로 배워볼 것입니다.
군집화 알고리즘
(A) K-means와 K-medoids

두 알고리즘은 주어진 데이터의 공간 상의 점들을 서로 가까운 점들끼리 묶어 몇 개의 군으로 나누는 군집화기법을 말합니다.
이 때의 최소화된 거리는 거리 차의 분산을 기준으로 비교하게 됩니다.
(B) 개체 사이 거리 계산 방법


이 때 두 개체의 거리 차이를 계산하는 방법으로 유클리디안 거리와 맨해튼 거리를 공부했습니다.
구체적인 수식을 암기할 필요는 없지만 계산 방법의 논리적 구조를 이해하고 있다면
군집화 알고리즘 전반에 대해서도 더 잘 이해할 수 있겠지요!
(C) 알고리즘 순서도

지금까지 배웠던 각각의 개념들을 활용하면 위의 알고리즘 순서도 역시 쉽게 이해할 수 있습니다.
- 전체 데이터에 대해 내가 임의로 나누고 싶은 군집의 개수 (K)를 지정하고,
- 특정 중심점(K개)로부터 거리측정 공식을 사용하여 거리를 도출하고,
- 이 거리를 최소하는 방식으로 군집을 재배치해줍니다.
이 과정을 군집화가 완료되는 시점까지 반복해주고 더 이상 변동이 없다면 완성!
아래 예시와 같이 정렬되지 않은 raw 데이터를
위의 알고리즘을 통해 군집화할 수 있습니다.

재미있는 실습시간

지금까지 공부한 군집화의 개념을 실습을 통해 더 재미있게 이해할 수 있었는데요,
큐밀리들로부터 몇 가지 항목에 대한 설문을 조사받고
해당 데이터를 활용하여 몇 가지 두드러지는 성향에 따라 군집화해봤습니다!
나랑 비슷한 성향을 가진 큐밀리들은 누구인지도 확인해보면서
재미있게 마무리한 2번째 세션이었습니다.
다음 세션 일지에서는 마지막 세션!
카카오뱅크 유재흥 연사님의 CRM 마케팅 실무편에 대해 다뤄보도록 하겠습니다.
그럼 다음 포스팅에서 다시 만나요!
(안녕)
*위 자료에 대한 저작권은 양용준 교육자에게 있습니다. 무단 전재 및 재배포를 금지합니다.*
'KUSITMS 활동 > 세션 일지' 카테고리의 다른 글
| [큐시즘 20기 5차 세션] 빅데이터 시각화 및 아두이노 실습 (0) | 2019.11.15 |
|---|---|
| [큐시즘 20기 4차 세션(3)] 카카오뱅크의 CRM 마케팅 (0) | 2019.11.07 |
| [큐시즘 20기 4차 세션(1)] CRM 마케팅의 이해 (0) | 2019.11.07 |
| [큐시즘 20기 1차 세션(2)] '디자인 씽킹'의 개념과 이를 활용한 실습까지! (0) | 2019.11.04 |
| [큐시즘 20기 1차 세션(1)] 20기 첫 정기교육의 시작, '스타트업이란?' (0) | 2019.11.04 |



