1주차 정기교육세션 : AI Paper Trend in 2hours by 채필재
안녕하세요.
저는 #큐시즘 #한국대학생IT경영학회 #21기 대외홍보팀원 박수완입니다. ꒰◍ˊ◡ˋ꒱੭⁾⁾
첫 세션은 저번주 토요일, 2월 29일로 예정되어 있었으나
코로나19 바이러스 확진자가 늘어나면서 전체 일정이 한 주씩 미뤄졌습니다.
또한 당분간 세션은 큐밀리들이 원하는 세션을 선택하여 돌아가며 세션을 수강하는
소규모 세션의 형태입니다.

"원하는 주제 중 하나 선택하시면 됩니다!"
이 외에도 코로나 감염예방을 위하여
- 교육장 내 손소독제 비치
- 마스크 착용 필수 공지
- 스터디, 소모임, 조모임 등 소규모 활동 활성화
등등 바이러스 확산 방지와 학회 활동 유지를 위해 열심히 노력 중이랍니다 ( •̀ᄇ• ́)ﻭ

첫 정기교육 세션은
○ 박세희 교육자님의 Blockchain & LTE Cell Search - Cocos Tutorial
● 이재원 교육자님의 퍼포먼스 마케터의 Google Analytics
○ 채필재 교육자님의 AI Paper Trend in 2 hours
● 도연희 교육자님의 머신러닝과 딥러닝 알고리즘
○ 박강민 교육자님의 창업자의 퍼포먼스 마케팅
의 총 5가지의 주제로 진행되었습니다.
모두 유익한 세션들이였는데요, 먼저 불타오르는 세션 현장 사진들을 보여드리도록 하겠습니다.




아 데였다 너무 뜨겁다 큐밀리들의 열.쩡 😎👍
이번 포스팅에서는
채필재 교육자님의 AI Paper Trend in 2 hours를 다뤄보겠습니다:)

https://www.youtube.com/watch?v=P2uZF-5F1wI
세션 시작 전에 잠깐 봤던 영상인데,
딥러닝을 통해 모나리자에 생명을 부여한 것이 정말 신기했어요! +.+
이런 식으로 예시 위주의 다양한 AI 이슈들이 등장할 예정입니다!

인공지능은 크게
- Vision
- Natural Language Processing (NLP)
- Audio
의 분야로 나눌 수 있습니다.
" Vision "
먼저 Vision은 이미지를 다루는 분야로,
그 중 가장 대표적인 task는 인간이 판별하기 힘든 이미지까지 분류할 수 있을 정도로 발전한
Image classification입니다.

차는 차끼리, 집은 집끼리 픽셀 단위로 나뉘고 (Image Segmentation)
글자에 맞는 사진들을 분류해내는 것(Image Classification)이
Vision의 대표적인 예시라 할 수 있습니다.

사진 속의 글자를 읽어 문자로 변환해주는 것을
OCR (Optical Character Recognition) 이라 하는데요,
금융 어플리케이션에서 신분증 사진만으로 정보를 입력할 수 있도록 하는 것처럼
실생활에서도 유용하게 쓰이고 있다고 합니다.

그리고 정말 신기했던 것 중 하나!
이 사진들 중에 실제 사람은 몇 명이고, 인공지능으로 만들어 낸 사람은 몇 명일까요?
정답은
모두 인공지능으로 만들어 낸 사람이라는 사실!
이러한 기술을 GAN (Generative Adversarial Nets) 이라고 합니다.
Generator는 Discriminator가 구별하지 못하도록 이미지를 만들어 내고,
Discriminator가 가짜 이미지와 실제 이미지를 판별해내는 과정을 통해
앞의 이미지와 같이 감쪽같은, Balance가 맞는 이미지가 탄생하게 된답니다!

Super resolution은 이미지 화소를 높이는 기술로,
1960년대 영상이나 이미지를 자연스럽고 고화질의 결과물로 재탄생시킬 수 있습니다.

Style transfer는 말 그대로 이미지의 스타일을 바꿀 수 있는 기술입니다.
Input 과정에서처럼 '배 사진을 도시사진 풍으로 바꿔줘!'라는 요청에 맞는 결과물을 낼 수 있는데요,
맨 오른쪽이 가장 최신의 성능이라고 합니다.
" NLP "


NLP (Natural Language Processing) 은 말 그대로 자연어처리를 뜻하는데요,
일상생활에서의 번역부터 텍스트에서 감정을 캐치하는 역할까지 다양한 역할을 수행합니다.
초반에는 1 한개를 제외하고 나머지를 모두 0으로 표현한
One hot Vector Representation 의 방법을 통해 자연어를 처리했고,
2012년 즈음에는 의미가 비슷한, 가까운 단어끼리 묶어주는 Word2Vec 방법이 등장했습니다.


그리고 문장을 처리하는 데 있어서는 RNN과 Attention에 주목할 수 있습니다.
'This is an example' 이라는 말을 번역할 때,
RNN는 처리 순서가 중요한 자연어의 특성을 살려 단어를 나열한 반면,
Attention는 단어 하나하나가 어떤 단어와 가까운지 가중치를 두기 때문에
단어마다의 의미와 연관성까지 판단할 수 있습니다.
'예문'에 가장 가까운 단어가 'example'임을 파악하여 번역할 수 있겠죠?
중요도가 높은 단어를 알려주는 Attention을 잘 활용한다면
번역 뿐만 아니라 논문 요약, 주제 찾기 등도 수월하게 할 수 있을 것 같아요!
뿐만 아니라 Attention은 이미지나 오디오에도 적용이 가능하다고 합니다.


Pretraining은 방대한 양의 이미지로 먼저 거대하게 학습을 시키는 것이고,
Finetuning은 만들어진 모델을 주어진 task에 맞게 미세 조정을 하는 기술입니다.
최고의 개발자 채필재 교육자님 ^*^께서 인공지능 중에서 가장 중요한 기술 중 하나라고 하셨으니, 주목해주세요!😎
NLP에서 주로 사용되는 Pretraining은 크게
1) Masked Language Model, 2) Next Sentence Predicition 의 과정으로 나눌 수 있습니다.

Masked Language Model 과정을 통해 문장 속 단어에 [마스크]를 씌어 학습하고,
Next Sentence Prediction을 통해 다음 문장이 자연스러운지 여부를 맞춰봅니다.
자연스럽다면 IsNext, 아니라면 NotNext의 결과가 나옵니다.

다음으로 ZeroShot은 Finetuning을 하지 않고 Pretraning으로만 학습하며
엄청 많은 데이터를 가져오기만 한 것으로,
교육 자료에서 표현된 것과 같이 'Just Guess' 한 것이라고 이해하시면 될 것 같습니다!
NLP의 다양한 기술들을 살펴보았는데요,

이렇게 한 두 문장만 써주면 모델이 알아서 그 다음 문장을 써 소설이나 대본을 완성시키기도 하고,
(이는 pretraning을 했기에 가능했다는 사실╰( ͡° ͜ʖ ͡° )つ)

자연스러운 대화와 농담을 할 수 있는 Chatbot을 만들 수도 있으며,

감정을 분석하는 모델을 만들어볼 수도 있답니다!
" Audio "

마지막으로 Audio에 대해 설명해드리겠습니다.
Audio에서는 말 그대로 소리와 관련된 인공지능 예시들을 소개해 드리겠습니다!!
https://www.youtube.com/watch?v=FhPI5lbyz-I
Speaker Diarization은 목소리의 파형을 분석해, 어떤 사람의 목소리인지 구분해 자를 수 있는 기술입니다.
어디서부터 어디까진가 A가 말한 내용인지, B가 말한 내용인지 구분하기 때문에 회의록 작성에 유용할 것 같은데요!
아쉽게도 아직까지는 덜 발달한 분야라 말이 겹치면 정확도가 많이 떨어지는 등의 한계가 있다고 합니다. •́︿•̀

TTS 는 Text To Speech의 줄임말로, 텍스트를 스피치로 바꿔 읽어주는 기술입니다.
영어 사전을 검색해서 발음을 듣고 싶을 때처럼 실생활에서도 많이 쓰이고 있는데요,
문맥까지 파악해 과거형 read와 현재형 read을 구분해 다르게 읽을 정도로 많이 발전했다고 합니다.
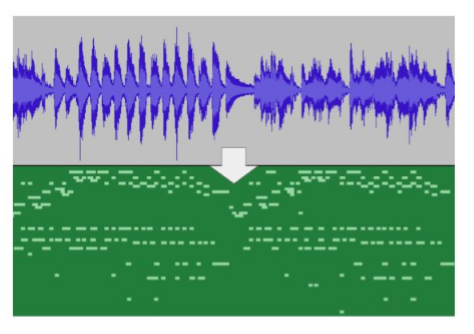
AMT는 Automatic Music Transcription의 줄임말로, 음악을 악보 형태로 바꿔주는 기술을 의미합니다.
뿐만 아니라 강약조절, 테크닉 등을 반영합니다.
https://magenta.tensorflow.org/onsets-frames
여기서는 미디 형식으로 바꿔주고 있네요!
얼마나 자연스러운지 들어보세요 ㅎ0ㅎ
Onsets and Frames: Dual-Objective Piano Transcription
Update (9/20/18): Try out the new JavaScript implementation!Update (10/30/18): Read about improvements and a new dataset in The MAESTRO Dataset and Wave2Midi...
magenta.tensorflow.org

다음으로는 큐밀리들의 반응이 가장 좋았던 것!
Singing Voice Synthesis에 대해 소개해드리려고 해요 👀
목소리 몇 초만으로도, 학습된 모델에 넣어 그 목소리로 부른듯한 노래를 뚝딱 만들어 낼 수 있는데요,
긴 말 말고 예시 한 번 들어보시죠!
https://www.youtube.com/watch?v=oKjuoR6Y54g
이게 실제로 부른 노래가 아니라니 😱 정말 신기해요
그리고 너무 귀여운 영상인데,,
https://www.youtube.com/watch?v=teehYuZO4g4&feature=emb_rel_end
이처럼 노래를 분석해서 그에 맞는 자연스러운 안무를 창조할 수도 있다고 합니다!
관절 포인트를 모델링해서 만든다고 합니다.
실제로 안무가들이 관심을 가지고 보고 있다고 하니, 기술의 발전이 정말 놀랍다는 걸 실감했어요🤔

딥러닝의 기본적인 개념은 Data Driven입니다.
0.1%의 오차라도 줄이기 위해 깊고 많은 데이터를 쌓아 정확도를 높이는 연구가 많았습니다.
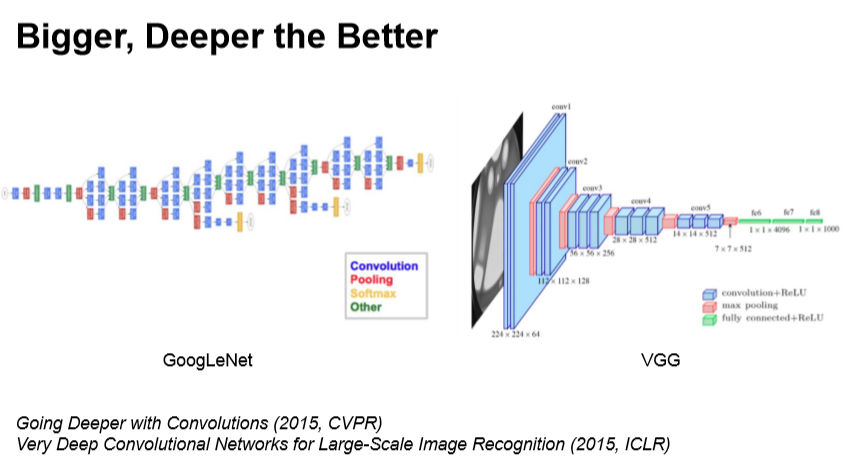
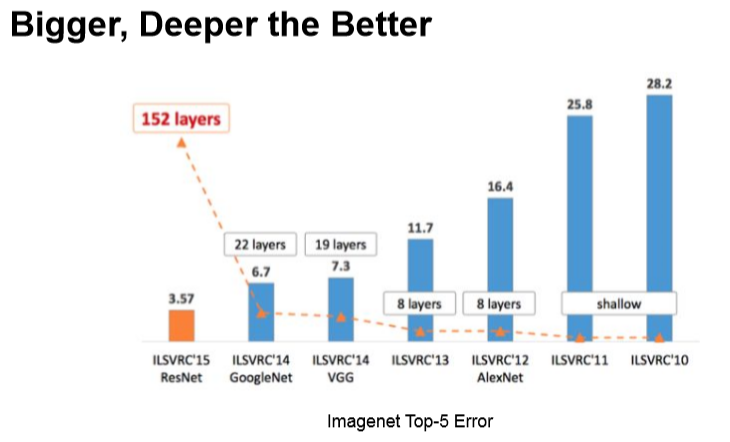
이처럼 딥러닝은 크게 많이 깊은 데이터를 쌓아 연구를 진행해왔지만,
최근에는 architecture를 바꿔 깊게 쌓지 않고도 딥러닝이 가능하게 하는 연구가 trend라고 합니다.

딥러닝의 최신 트렌드는 Efficient & Big 로
무작정 데이터를 늘려 나가는 것이 아니라 최적의 set을 효율적으로 찾아가는 중이라고 합니다.
이렇게 정말정말 유익했던 1차 세션 내용 포스팅이 끝났는데요!
전체적인 AI 관련 이슈를 한 번 싹 훑어볼 수 있는 경험이었던 것 같아요 😃😃
그럼 다음 주에도 알차고 유용한 세션 일지로 찾아올게요 ♥
준비해주신 다섯 분의 교육자님과 열심히 들은 큐밀리들 모두 수고하셨습니다 🥰

*위 자료에 대한 저작권은 큐시즘 교육기획팀에게 있습니다. 무단 전재 및 재배포를 금지합니다.*
'KUSITMS 활동 > 세션 일지' 카테고리의 다른 글
| [큐시즘 22기 1차 세션(1)] 생각하는 디자인, Design Technology와 프로토타이핑 실습! (0) | 2020.09.02 |
|---|---|
| [큐시즘 21기 2차세션] 일상 속에서 상용화되고 있는 Blockchain & LTE Cell Search의 개념과 원리 쉽게 배우기!! (0) | 2020.03.18 |
| [큐시즘 20기 6차 세션] 핀테크 금융, 혁신의 DNA를 품다 (0) | 2019.11.28 |
| [큐시즘 20기 5차 세션] 빅데이터 시각화 및 아두이노 실습 (0) | 2019.11.15 |
| [큐시즘 20기 4차 세션(3)] 카카오뱅크의 CRM 마케팅 (0) | 2019.11.07 |



