안녕하세요, 큐밀리 여러분!
지난 블로그 일지에 이어, 티스토리 3차 세션 일지를 담당하게 된
큐시즘 대홍 23기 팀원 박수현입니다 :D
제가 일지를 작성할 강의는

이승희 교육자님의 "금융 데이터 분석과 인공지능 투자"입니다!
우선 전반적인 강의 내용을 요약하기에 앞서,
목차를 설명드리자면, 다음과 같습니다!

그럼, 이제 금융 개론부터 시작해보겠습니다!
01. 금융 개론(1) : 금융 이해와 재무 설계의 중요성
슬프게도, 우리나라는 금융 문맹국입니다.
OECD의 최소 금융 이해 수준 점수보다 우리의 평균이 낮다고 하네요! :(
절반가량은 금융 이해력 테스트에서 낙제를 받았다고 합니다.
요즘은 젊은 층에서 주식 투자를 많이 접하고 있지만,
여전히 금융에 대한 기본적인 이해는 부족하지 않나 싶습니다.
그런 의미에서 이승희 교육자님은 우리의 미래를 위한 재무 설계 플랜을 소개해주셨는데요!
첫 번째, 3가지의 저축을 동시에 진행한다.
단기 : 은행 / 중기 : 증권 / 장기 : 보험
나름대로 단중장의 목표를 생각해서 위의 3가지로 준비하면 되고,
비율은 6:2:2 정도가 적합하다고 하네요!
두 번째, 4개의 통장을 개설해 관리한다.
1. 급여통장 2. 지출통장 3. 투자통장 4. 비상금 통장
위의 4가지를 만들면 되는데, 매달 들어오는 급여에서 생활비를 지출 통장에 넣고 남은 돈을 투자 통장에 넣습니다.
그리고 한 달 생활 후 잔액이 남는다면, 바로 비상금 통장에 넣어두면 됩니다.
세 번째, 절세플랜 세테크!
재테크 대신 세테크라는 말이 있듯, 세금을 아끼는 방법도 여러 가지가 존재합니다.
그중에서 승희 교육자님께서는, 소득 공제와 세액 공제에 대해서 설명해주셨는데요!
1. 소득 공제란,
말 그대로 자신의 소득에서 소득이 없던 것처럼 빼준다는 뜻입니다.
주택청약종합저축을 예시로 들면 연 240만 원을 저축할 경우, 한도 40% 96만 원을 소득에서 공제받게 됩니다.
세금을 계산할 때 물론 소득에 비례하겠지만 세금을 간단히 20%라고 잡으면, 96만 원의 20%를 아껴서 20만 원을 아끼게 되는 것입니다. 신용카드는 급여 25% 초과 금액의 15%로 최대 300만 원을 공제받을 수 있습니다.
연봉 5000이라고 하면 신용 카드로만 연 1250만 원을 지출했을 때, 그 이후부터 지출의 15%가 공제된다는 것입니다.
체크카드와 현금영수증으로는 신용카드의 2배인 30%가 공제됩니다.
2. 세액 공제란,
산정된 세금에서 빼주는 것입니다.
보장성보험은 연 100만 원 한도 12% 세액공제를 받을 수 있습니다.
연 100만 원 이상 보험료를 냈다면 12만 원을 돌려받을 수 있다는 뜻입니다.
IRP, 연금저축은 연 5500만 원 소득을 기준으로 초과 시 12%, 미달 시 15%를 공제해줍니다.
여기까지 간단한 재무설계 팁을 골라서 설명드렸고,
이제는 본격적으로. 데이터 분석과 A.I 투자를 위한 금융 공부를 시작해보겠습니다!
01. 금융 개론(2) : 증권 분석_ 이동평균성 분석 및 지표 분석
증권 투자를 할 때엔, 증권에 대해 충분히 알아보고 투자해야 합니다.
물론 충분히 투자 가치를 느낀 기업에 바로 투자할 수도 있지만,
펀드 등 포트폴리오를 구성하여 투자를 하기 위해서는 증권 선택 후 아래와 같은 증권 분석을 진행합니다.

증권 분석 방법 중 기술적 분석에 대해서 알아보겠습니다.
기술적 분석 방법에는 추세분석, 패턴 분석, 캔들차트, 이동평균선 분석, 지표 분석 등이 있습니다.
특히 이동평균선과 지표 분석은 데이터 분석이나 A.I투자에서 응용되어 사용될 예정이니,
두 개념에 대해서만 짚고 넘어가 보겠습니다!

우선 이동평균선이란, 말 그대로 주가 이동의 평균치를 선으로 이어서 나타낸 것을 말합니다.
일정 기간의 종가들을 평균으로 나타낸 선이며,
5일 선은 5일간의 이동평균치, 100일은 100일간의 이동평균치를 말합니다.
이동평균선은 지수 분석에서 아주 크게 활용되는데,
그래프의 작은 노이즈들을 제거해주어 넓은 시각에서 지수의 흐름을 볼 수 있게 합니다.

저희는 이동평균선 분석 방법 중 그랜빌 투자전략을 보겠습니다!
왼쪽은 다우이론으로, 매상 과분 공침 6 국면으로 주식의 국면을 결정하는 분석 방법입니다.
이동평균선은 주식을 평균화시켜 진동(노이즈)이 제거된 선입니다.
이동평균선을 사용하면 주식의 작은 이슈들이 제거되어 순수한 주가의 중장기 추세만 볼 수 있게 됩니다.
위의 이미지 우측에, 그랜빌 8개 그래프에 각각 번호별 설명이 자세하게 나와있으니 확인해주세요! :)

다음 이동평균선 분석 방법인 골든/데드크로스입니다!
이 분석도 이동평균선을 그려서 비교하지만, 그랜빌 투자전략과 다른 점은
그랜빌 투자전략에서는 이동평균선 1개와 증권선을 비교했지만, 여기서는 이동평균 2개를 비교한다는 것입니다.
대신 이동평균선의 평균을 짧고 길게 나눠 단기, 장기로 구별해 비교합니다.
만약 단기 이동평균선이 장기 이동평균선을 상승 돌파한다면 골든크로스로 매수신호가 되고,
하락 돌파한다면 데드크로스로 매도신호가 됩니다.

다음은 지표 분석입니다.
지표 분석에서는 스토캐스틱과 RSI라는 지표들을 알아보려고 하는데요!
뒤의 실습에서 A.I투자에서 이 지표들을 A.I에게 학습시킬 예정이기 때문입니다 :)
스토캐스틱은 아래의 3가지 지표로 존재합니다.
Fast%k, Fast%D=Slow%K, Slow%D
RSI는 0~1 사이의 값인데 다음의 수식을 넣었을 때
0.7 이상이면 과열로 보고 매매를 중단,
0.3 이하일 때는 침체로 보고 매매를 시작하는데
판단할 수 있는 지표입니다.
지금까지 설명드린 금융 개론과 증권 분석에 대한 이해를 기반으로,
이제 데이터 분석 A.I에 대해서 더 깊이 있게 공부해보겠습니다!
02. 데이터 분석 A.I : 도메인 지식을 기반으로 한 분석과 머신러닝
데이터 분석은 주어진 데이터에서 우리가 활용할 수 있는 정보를 추출해내는 것을 말합니다.
이 업무에는 여기 쓰여있는 통계, 수학, 프로그래밍 기술과 함께 "도메인 지식"이라는 것을 필요로 합니다.
도메인 지식은 데이터를 분석할 때 그 데이터에 대한 사전 지식을 뜻하는데요!
데이터 분석이나 A.I는 해당 부분의 도메인 지식을 가졌을 때 특히 효과가 큽니다.
아무래도 기본적인 도메인 지식을 더 많이 가지고 있을 때, 유의미한 인사이트를 뽑아낼 수 있겠죠!
금융 측면에서는, 신용 평가 모델 구축과 고객 응대 챗봇, 로보 어드바이저 쪽에서
데이터 분석과 A.I의 성과를 거두고 있습니다.
우리나라의 국내 2017년의 장내 상장기업 수는 2000개를 넘었고,
세계 상장 주식까지 합치면 어마어마한 수의 데이터가 존재하고 있습니다.
데이터 측면에서 충분히 빅데이터의 잠재력을 가지고 있는 시장이라고 볼 수 있겠습니다!
저희는 파이썬을 통해 금융 데이터 분석을 진행해보았는데요.
파이썬을 이용하는 이유는 다음과 같습니다!

아무래도 파이썬의 장점은 바로, 문법이 간결하다는 점이죠!
또한 라이브러리 활용에 대한 장점이 있어 데이터 분석 분야에서 더욱 많이 활용되고 있습니다.
보통 데이터 분석 과정은,
데이터 준비 > 데이터 관찰 > 데이터 클렌징 > 데이터 탐색 > 데이터 시각화

위의 순서로 진행됩니다.
저희도 실습에서 해당의 순서로 주가 데이터를 분석해보았는데요.
저희는 FinanceDataReader라는 파이썬 모듈을 통해,
데이터 준비 단계인, 주가 엑셀 데이터를 구글링 하지 않고도 손쉽게 다운로드하여 진행했습니다 :)
03. 파이썬 실습 : 파이썬을 통한 데이터 분석과 머신러닝
우선 이번 분석 실습에서 사용한 "라이브러리"들을 먼저 간단히 소개해드릴게요.
Numpy, Pandas는 각각 행렬과 데이터 프레임을 만들 수 있는 데이터 과학 모듈입니다.
데이터 분석의 첫걸음마를 떼는 모듈이라 보시면 될 것 같습니다.
FinaceDataReader는 위에서도 말씀드렸다시피 주가와 지수 데이터를 불러올 수 있도록 해줍니다.
Tensor flow는
Sklearn은 머신러닝이나 데이터 과학 쪽에서 다양한 메소드를 지원해주는 라이브러리입니다.
자, 그럼 실습을 복기해볼까요?
저희는 실습을 위해 제일 먼저, Jupyter Notebook을 실행시켜
FinaceDataReader 라이브러리를 불러와주었습니다.
이후 아래의 이미지처럼, data라는 변수에 주식 코드를 입력해주어
특정 회사의 증권 데이터를 확인해 볼 수 있었는데요!

저희가 확인해본 회사는 바로, 삼성전자입니다!
위 이미지에서 빨간색 글자로 보이는 숫자("005940")가 바로 삼성전자의 증권 번호인데요!
해당 번호는, 네이버에 검색하면 나오는 증권정보의 회사명 우측에서 확인할 수 있습니다.

위 이미지처럼, 삼성전자는 005930으로 확인되죠?!
FinanceDataReader 라이브러리를 이용하면, 네이버에 증권 정보만 검색해본다면
어떤 회사의 증권 데이터도 분석해보고 확인해볼 수 있어서 너무 편리한 것 같습니다!

아까 data라는 변수명으로 설정해두었던, 삼성전자의 증권 정보와 통계를 가져오기 위해
data.info()data.describe()라는 코드를 입력하여 불러와보았습니다.

data.head()
data.tail()
다음의 코드도 입력하여 상위 데이터와 하위 데이터도 추출해볼 수 있었고,

def get_MA(df):
MA_26=df['Close'].『olling(26).mean0
MA_52=df['Close'].『olling(52).mean0
df=df.assign(MA_26=MA_26,MA_52=MA_52).dropna0
return df
#스토캐스틱
def get_stochastic(df, n=l5, m=S, t=3):
#n일중죄고가
ndays_high = df. High.rolling(window=n, min_periods= 1 ) .maxO #n일중죄저가
ndays_low = df.Low.rolling(window=n, min_periods=l).minO
#Fast%K계산
kdj_k = ((df.Close -ndays_low) / (ndays_high -ndays_low))*lOO
#Fast%D (=Slow%K) 계산
kdj_d = kdj_k.ewm(span=m).meanO
#Slow%D계산
kdj」= kdj_d.ewm(span=t).mean()
#dataframeOII 컬럽 추가
df = df.assign(kdj_k=kdj_k, kdj_d=kdj_d, kdj」=kdj」).dropnaO
return df
def rsi(values):
up = values[values>Ol.meanO
down = -1"values[values<O).mean() return 100 " up / (up ... down)
data=get_MA(data)
data=get_stochastic(data)
data=get_MA(data)
data=get_stochastic(data)
data['Momentum_1 D'] = (data['Close']김ata['Close'].shift(l))
data['RSI_14D'] = data['Momentum_1 D'].rolling(center=False, window=14).apply(rsi) data=data.dropnaQ
data = data.drop(labels = ['Momentum_10'], axis=1)
위의 코드를 입력해주어, 저희가 볼 증권 정보에 최고가와 최저가 등의 추가 데이터를 추출해보았습니다!
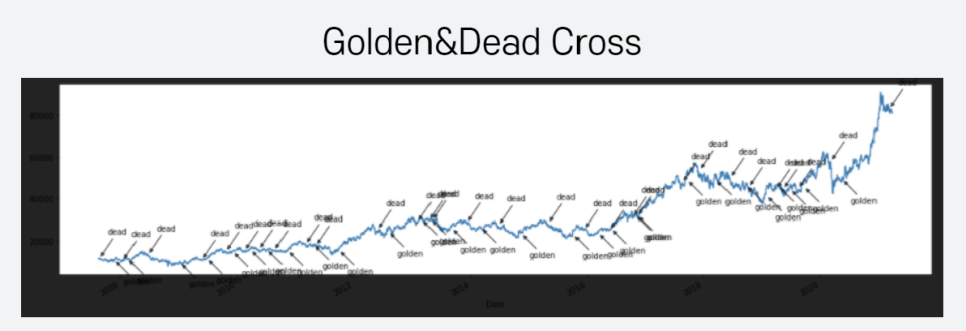
또한, 하단의 코드를 통해 위에서 설명드렸던 "골든&데드 크로스"도 확인해 볼 수 있었습니다.
data = fdr.DataReader("005930"," 1997-03-01 ") prev_val=O
f=data["Close"].plot(figsize=(20,5))
prev_val=O
f=data["Close"].plot(figsize=(20,5))
data["diff"]=data["MA 26"]-data["MA 52"] for k,v in data[" 1997-1-1 ":]["diff"].iteritems():
if(prev_val*V)<O:
if v>prev_val:
f. annotate("golden " ,xy=(k,data[" MA_52 "][k]) ,xytext=( 10,-30) ,textcoords= "offset points" , arrowprops=dict(arrowstyle='-1 >'))
else:
f.annotate("dead",xy=(k,data["MA_52"][k]),xytext=(1 O,30),textcoords="offset points", arrowprops=dict(arrowstyle='-1 >'))
prev_val=v
이후, 저희는 이동평균선 예측을 통한 A.I 투자를 진행해보았는데요!
처음에는 FinanceDataReader에서 제공하는 지표(시가, 종가, 고가, 저가, 주식수, 전일대비 수익률)를 이용해서
딥러닝 모델로 주식의 상승, 하락을 분류 예측하였습니다.

그러자, 정확도 약 58%라는 안 좋은 결과가 나왔습니다.
정확도가 저조한 첫 번째 이유는, 주식 시장은 변동성이 너무 커서 (주식 시장에서는 Noise라고 부릅니다.)
하루하루의 값을 예측하기에는 무리가 있기 때문입니다.
두 번째 이유는, FinanceDataReader의 6개의 지표만으로는 주식의 흐름을 예측하기에는 정보가 너무 적어 한계가 있었기 때문입니다.
저희는 첫 번째 이유를 개선하기 위해 하단의 코드를 입력해주어 전일의 종가를 통한 내일의 종가 예측이 아닌,
내일의 이동평균선을 예측하도록 하였습니다.
y=[]
for x in range(1,len(df)-1 +1 ) :
if(df["Close"][x-1] > df_MA[1+(x-1)]):
y.append(O)
else:
y.append(1)
df = df[:-1 ]이 방법으로는 내일의 주식의 등락을 직접 예측하지는 못하지만,
noise가 제거된 주식 이동평균선의 흐름을 예측할 수 있게 됩니다.
또한, 두 번째 이유를 개선하기 위해 하단의 코드를 사용해 스토캐스틱과 RSI지표를 추가하였습니다.
#스토캐스틱주가
df=get_stochastic(df)
#RSI 주가
df['Momentum_lD'] = (df['Close']-df['Close'].shift(l)) df[' RS1_14D'] = df[' Momentu m_lD'] .rolling(center=Fa lse, window=l4).apply(rsi)
df=df.dropna()
df=df.drop(labels = ['Momentum_lD'], axis=l)

그러자, 종가를 통해 이동평균선을 예측한 결과의 정확도가 91%까지 올라가는 결과를 보여주었습니다!
실제 금융권에서 이용되는 A.I 투자 모델은, 이와 같은 A.I 솔루션들을 종합하여 만들어지는 것이라고 하네요! :)
마무리
저는 실습을 하면서, 요즘 제가 개인적으로 관심이 있는
"덱스터"라는 회사의 증권 정보를 가져와 진행해보았는데요!
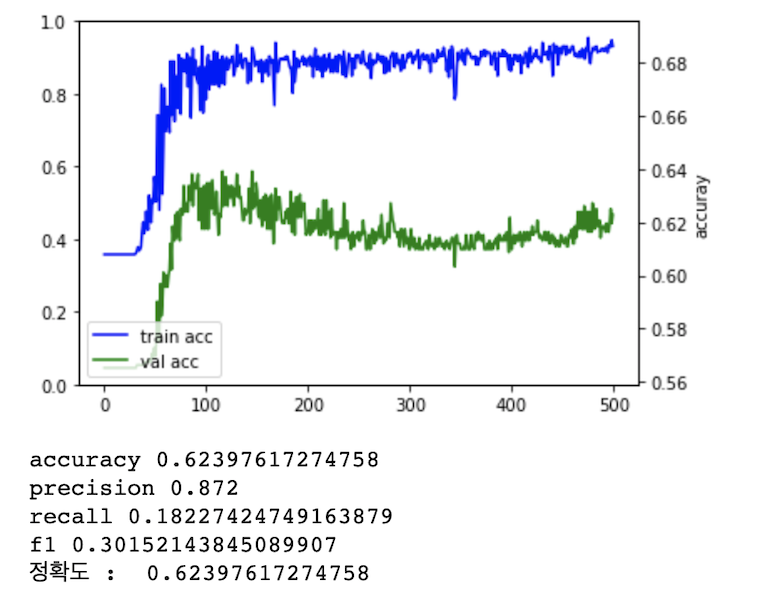

저 또한, 지표를 추가하고 나니 정확도가 62%에서 85%까지 상승했답니다!
실제로 제가 관심이 있는 회사의 증권 정보를 활용해 실습을 진행했더니
더 뿌듯하고 재미있었고, 강의로만 끝나는 교육이 아닌
저 스스로도 더 공부해볼 수 있는 수업이었다는 생각이 들었어요!
이번 세션을 들으셨던 다른 분들은 모두들 어떠셨나요?
저는 너무 해보고 싶던 분야지만, 늘 멀게만 느껴졌던 증권 데이터 분석이
조금이나마 가까워지고 익숙해졌던 보람찬 시간이었답니다!
이렇게 좋은 강의를 준비해주신 승희님께 다시 한번 박수 부탁드려요~~ :)
긴 글 읽어주신 분들 너무너무 감사하고,
그럼 저는 이만 들어가 보겠습니다!
지금까지, IT경영학회 큐시즘 23기
대외 홍보팀원 박수현이었습니다!
감사합니다 :)
'KUSITMS 활동 > 세션 일지' 카테고리의 다른 글
| 모바일 UX 기획과 프로토타입 디자인 실습 _ 권희성 교육자 (0) | 2021.04.19 |
|---|---|
| UIPath로 구현하는 RPA 업무 자동화 _ 박예진 교육자님 (1) | 2021.04.06 |
| [큐시즘 22기 1차 세션(2)] 데이터 과학자가 되기 위해 알아보는 데이터 분석에 대한 모든 것! (0) | 2020.09.02 |
| [큐시즘 22기 1차 세션(1)] 생각하는 디자인, Design Technology와 프로토타이핑 실습! (0) | 2020.09.02 |
| [큐시즘 21기 2차세션] 일상 속에서 상용화되고 있는 Blockchain & LTE Cell Search의 개념과 원리 쉽게 배우기!! (0) | 2020.03.18 |



